
There is a gap at the center of most digital asset management programs, and it is not the one most teams talk about.
The conversation usually goes like this: we need better metadata so users can find assets faster. And so organizations invest in taxonomy workshops, governance policies, mandatory fields, and controlled vocabularies. They train their teams. They build intake forms. They write metadata guides that live in SharePoint and get read approximately once.
Then the volume of content scales. Campaigns accelerate. Agencies and contributors multiply. And slowly, quietly, the metadata quality degrades. Fields get skipped. Tags get applied inconsistently. Assets arrive from production with nothing attached to them. The taxonomy that made perfect sense during the implementation project begins to fracture the moment it meets real operational volume.
This is not a people problem. It is an architecture problem. And predictive metadata is the most direct answer the industry has produced to date.
TL;DR
- Metadata quality fails at scale not because of poor contributor behavior, but because manual tagging and basic AI auto-tagging are structurally incapable of keeping pace with enterprise content volume, taxonomy complexity, and downstream system requirements.
- Predictive metadata is distinct from auto-tagging: it populates specific, configured structured fields such as dropdowns, controlled vocabulary categories, and compliance attributes, rather than generating loose descriptive keywords.
- Agentic DAM platforms are implementing predictive metadata through Librarian Agent architectures that automatically classify assets by content type and enrich both structured and unstructured metadata fields from the moment a file enters the system. Aprimo’s Librarian Agent is a leading implementation of this architecture.
- Predictive metadata can be configured to map to Customer Data Platform segment attributes in parallel with DAM taxonomy, enabling personalization programs to consume content without manual re-tagging.
- When predictive metadata detects brand or compliance risk signals at ingest, it automatically triggers review workflows, moving governance from downstream auditing to point-of-entry control.
- Arthrex achieved a 130 percent increase in content discoverability after deploying Aprimo’s Metadata Agent across 100,000+ images. SEH reduced content creation time by 88 percent.
See how Aprimo’s Librarian Agents use predictive metadata to automate content classification, governance, and workflows.
Why Metadata Quality Fails at Scale: The Real Structural Problem
Most DAM practitioners understand the surface issue: manual metadata entry is slow, inconsistent, and dependent on contributors who are primarily focused on getting their content into the system, not on cataloging it for future discovery.
Enterprise content operations research consistently identifies metadata quality and content discoverability as top operational pain points for DAM programs, and AI-enabled metadata enrichment has shifted from a differentiating capability to a baseline expectation for enterprise buyers. The gap is not in awareness of the problem. It is in the architecture available to solve it at scale.
The deeper structural problem runs in several directions at once, and addressing it requires being specific about where the breakdown actually occurs.
Taxonomy Governance Gap
Controlled vocabularies are built at a point in time. The business evolves. New product lines, new markets, new campaign types, new regulatory requirements. Taxonomy governance rarely keeps pace with operational reality, and when it falls behind, contributors start making judgment calls that accumulate into inconsistency at scale.
Metadata Completion Gap
Most DAM systems support rich metadata models: text fields, dropdown fields, date fields, relationship fields, classification-dependent fields. But the more sophisticated the model, the harder it is to populate consistently at upload. Teams end up with well-designed metadata schemas that are 30 to 40 percent populated in practice. Partially populated metadata is not just unhelpful; it actively misleads search results by creating false confidence that assets have been properly cataloged when they have not.
Context Alignment Problem
Metadata that describes an asset for one downstream use case may be wrong for another. A product image described accurately for internal catalog use may be missing the audience-segment attributes that a personalization engine downstream requires. The metadata model that serves DAM search does not automatically serve CDP-driven content delivery. These are parallel needs, and traditional metadata approaches force organizations to choose between them.
Scale Problem
Content production has scaled faster than any metadata governance program was designed to handle. An enterprise managing tens of thousands of assets, or in cases like Arthrex, more than 100,000 images, cannot staff its way to metadata quality. The math does not work. Manual cataloging at that scale produces exactly the kind of inconsistency that makes DAM search unreliable and erodes user trust in the system over time.
Delayed Metadata Problem
Metadata applied days or weeks after upload does almost nothing for discovery in fast-moving content operations. An asset without metadata at the moment of ingest is an invisible asset. For teams operating under campaign timelines, invisible assets get remade rather than reused.
Each of these failure modes compounds the others. The result is a DAM that is technically functional but operationally broken: content is in the system, but teams cannot reliably surface what they need.
What Predictive Metadata Actually Is (and What It Is Not)
The term gets used loosely, so it is worth being precise.
Predictive metadata in digital asset management is the automated population of specific, configured metadata fields using AI analysis of an asset’s visual and textual content, applied at the moment of ingest and governed by an organization’s defined taxonomy and field structure. It is distinct from general AI tagging in that it targets structured fields with controlled values rather than generating descriptive keywords.
The DAM industry has broadly moved toward AI-assisted metadata generation over the past several years. Most enterprise platforms now offer some form of automated tagging, visual recognition, or AI-assisted captioning. These capabilities represent real progress. But they have also created a terminology problem: the phrase “AI-powered metadata” covers an enormous range of capabilities, from basic keyword tagging to sophisticated structured field population, and treating them as equivalent leads organizations to invest in tools that solve the wrong part of the problem.
Predictive metadata is not auto-tagging. Auto-tagging, in its basic form, applies keyword tags to images based on visual recognition. It is useful, but it addresses only one layer of the metadata challenge. Tags like “woman,” “outdoor,” “product” are better than nothing, but they do not populate the structured metadata fields that actually power enterprise DAM search and downstream content operations.

Predictive metadata operates on a different level. It uses AI to analyze both visual and textual content in an asset and then populates specific, configured metadata fields based on what the system understands about the content and the organization’s defined taxonomy. Those fields can be dropdown fields with controlled values, free text fields like product descriptions or document abstracts, category fields, compliance-relevant fields like therapeutic area or regulatory indication, or audience-segment attributes mapped to a customer data platform.
The distinction matters enormously in practice. A system that tags an image with “jacket” and “orange” is providing visual recognition. A system that populates the Product Category field with “Outerwear,” the Primary Color field with “Tangerine,” and flags that the background color deviates from brand standards is performing predictive metadata. One produces noise. The other produces operational value.
Predictive metadata is also configurable, which is what separates it from general-purpose AI enrichment. Organizations can define which fields should be populated, what values are permitted, and what conditions should trigger downstream workflows when certain metadata patterns are detected. This configurability is what allows predictive metadata to serve not just discoverability, but brand safety, compliance review, and content governance.
Librarian Agents: Where Predictive Metadata Becomes Operational
Predictive metadata as a standalone capability is powerful. But its full operational value is realized when it is embedded within an agentic system that acts on content automatically, at the moment of ingest, without requiring human intervention for every asset.
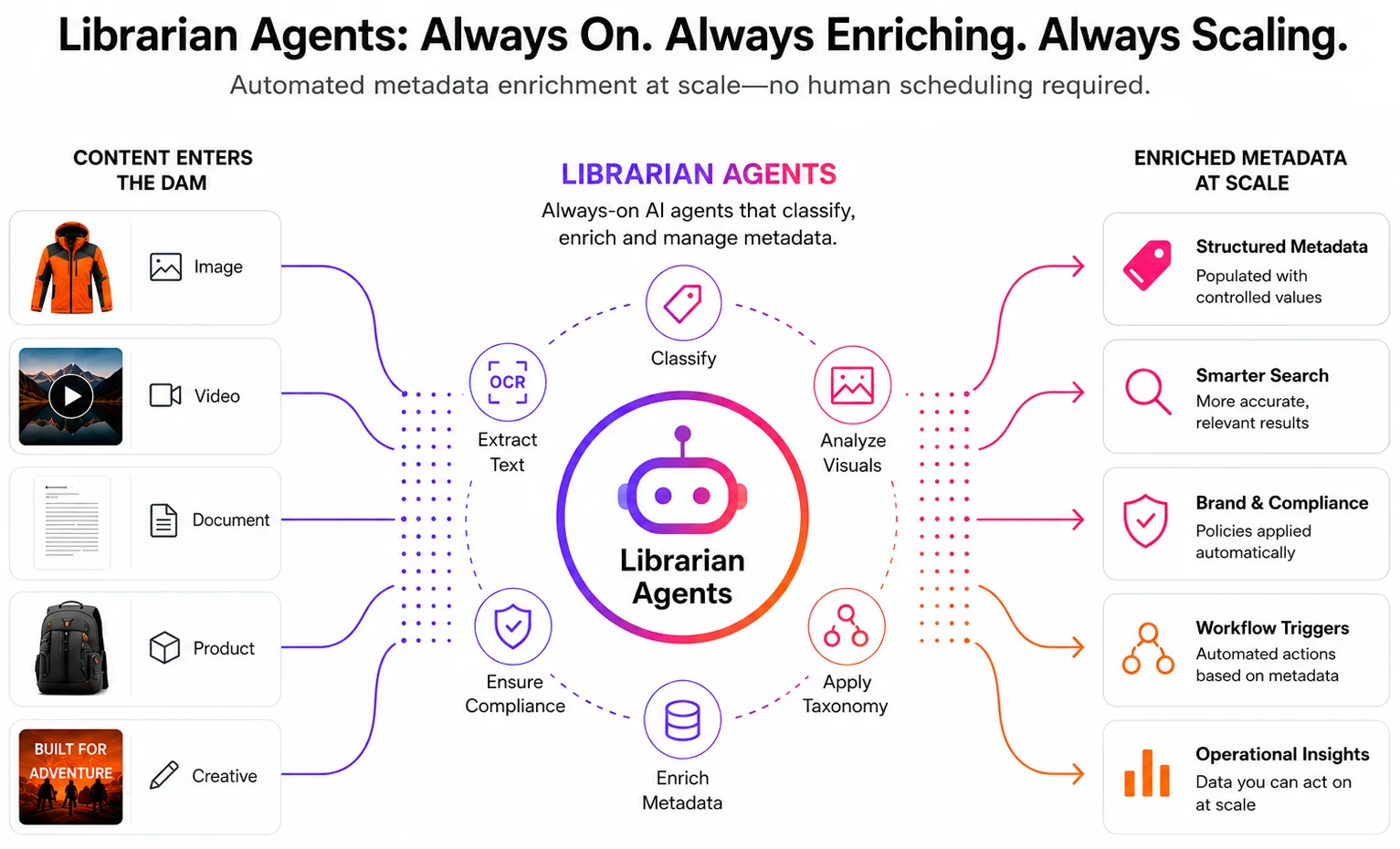
Librarian Agents continuously enrich content with structured metadata—automatically.
The emerging architecture for this in enterprise DAM is the concept of Librarian Agents: a persistent AI agent, or coordinated set of agents, whose specific responsibility is to classify, enrich, and manage content metadata as an automatic byproduct of content entering the system. Rather than a tool a cataloger uses, a Librarian Agent is an always-on process that runs independently of human scheduling.
Aprimo’s implementation of this architecture comprises two coordinated agents: the Metadata Agent and the Content Typing Agent.
The Metadata Agent analyzes visual and text-based assets the moment they are dragged and dropped into the DAM. It fills out both structured and unstructured metadata fields, automatically translates metadata for multilingual environments, applies brand-specific taxonomies, generates detailed captions that describe visual content in plain searchable text, and extracts embedded content like XMP data and OCR text to maximize metadata density. The result is that assets are immediately discoverable from the moment of ingest, not hours or days later when a cataloger gets to them.
The Content Typing Agent takes this one step further. Rather than applying a uniform metadata treatment to every asset, it automatically identifies what type of asset it is: a product shot versus a lifestyle image, a technical specification document versus a marketing brochure, a regulatory filing versus a campaign brief. Based on that classification, it determines which structured and unstructured metadata fields are appropriate for that specific content type and applies them accordingly. This content-type awareness enables downstream automation that would not be possible without it: content-specific review workflows, type-specific rendition generation, and type-aware search experiences.
Predictive metadata is the core AI capability powering both agents. It is what enables the system to populate those structured dropdown fields and controlled vocabulary fields that drive precise, reliable search, rather than producing a loose cloud of descriptive tags that approximate what is in an asset without actually organizing it.
What Does Predictive Metadata Have to Do With Personalization?
One of the most sophisticated and underappreciated applications of predictive metadata is its role in bridging DAM content to Customer Data Platform-driven personalization.
Here is the problem most organizations encounter. Personalization at scale depends on content being tagged with the same audience and segment attributes that the CDP uses to identify and target customers. But DAM metadata models are typically designed for asset management, not for audience segmentation. The taxonomy that makes an asset findable inside the DAM does not map to the segment fields that determine whether that asset gets served to a 35-to-45-year-old loyalty customer in the Midwest or a first-time buyer in an urban market.
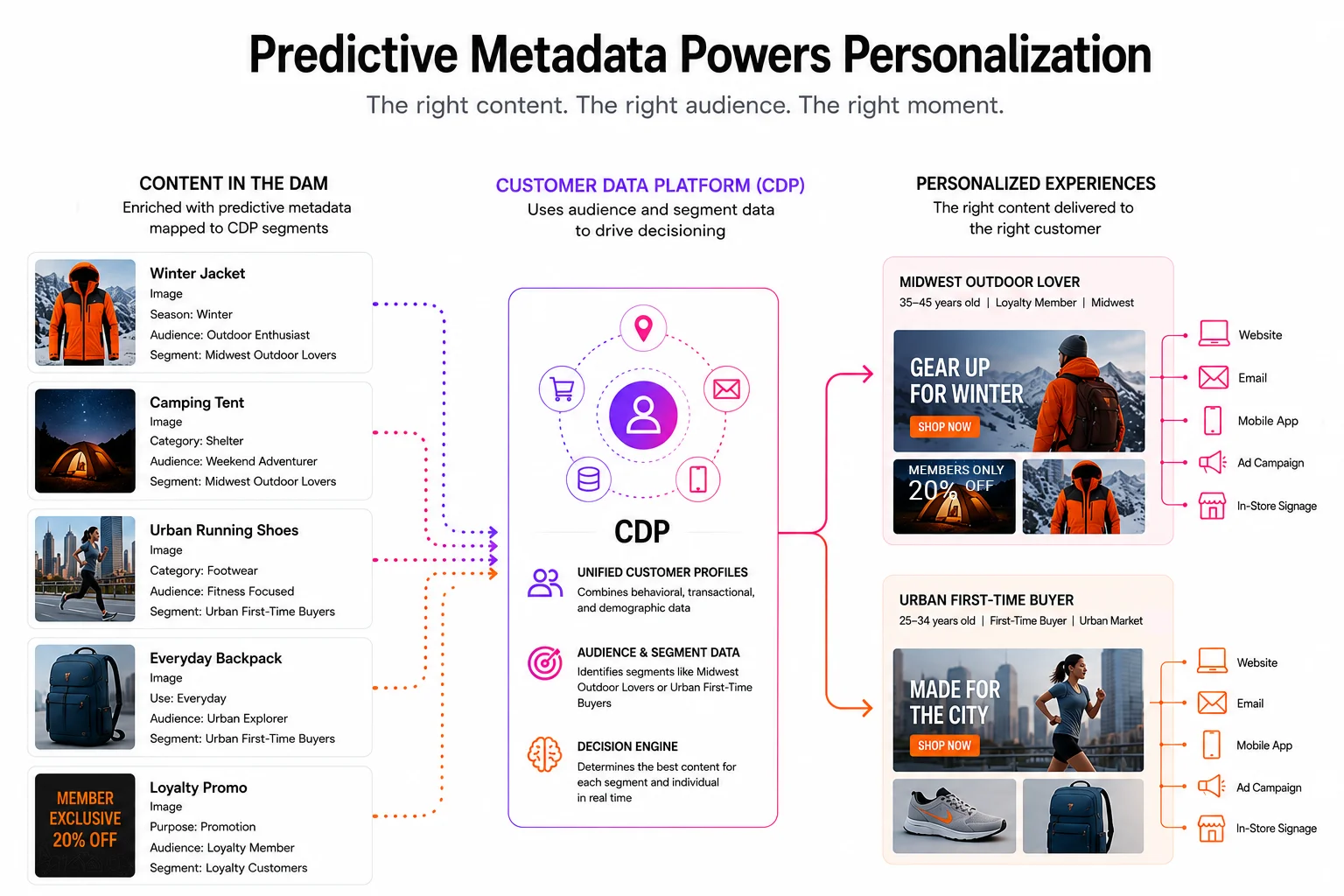
Every asset is enriched with the segment attributes your CDP needs, powering meaningful personalization at scale.
The traditional answer is manual dual-tagging: catalogers apply one set of metadata for DAM search and a separate set for downstream personalization. In practice, this doubles the manual burden and is the first thing that gets abandoned when volume increases.
Predictive metadata addresses this through parallel taxonomy support. When a DAM platform is configured to support parallel taxonomies, metadata fields that mirror the customer attributes and segment structures of a CDP can be populated automatically on both new and historical content. CDP mapping becomes an additional metadata dimension layered on top of the existing DAM taxonomy rather than a replacement for it. Both purposes are served simultaneously, without doubling the manual workload.
This is a configuration capability that mature enterprise DAM platforms are beginning to support, and it has direct implications for personalization programs. When every asset in the DAM carries the segment attributes the CDP needs to make decisioning, content becomes an active input into the personalization engine rather than a passive library that marketers have to bridge manually. The content supply chain closes.
Predictive Metadata as a Brand Safety and Compliance Trigger
One of the less obvious but operationally significant applications of predictive metadata is its ability to act as a compliance and brand safety trigger at the point of content ingest. When configured to recognize specific compliance-relevant attributes, predictive metadata can detect risk signals the moment an asset enters the DAM and automatically route it for review before it enters active use. This moves governance from a downstream, manual auditing function to an automated, point-of-entry control.
When predictive metadata is configured to recognize compliance-relevant attributes, it can identify risk signals at the point of upload and automatically trigger review workflows before those assets enter active use.
In a pharmaceutical context, predictive metadata can detect therapeutic area and indication fields in a document and flag an asset for regulatory review if those values suggest a compliance requirement is in scope. In a brand context, it can identify that a background color deviates from brand standards, that a specific color combination violates visual identity guidelines, or that personally identifiable information appears in a document that should not contain it. In each case, the asset does not simply enter the DAM and sit there waiting to be discovered. It enters the DAM, is assessed, and a review workflow is triggered automatically, with the detected metadata values surfaced for the reviewer alongside AI-assisted annotation guidance.
This is fundamentally different from compliance review as a downstream process. When review is triggered by predictive metadata at ingest, the governance function moves from after-the-fact auditing to point-of-entry control. Content that should not go live does not go live because it was never cleared in the first place.
What This Looks Like From the Moment a File Lands in the DAM
It is worth walking through the operational reality concretely, because the abstraction of “AI-powered metadata” obscures what is actually happening.
An asset arrives. It might be a product image from a creative agency, a regulatory document from a legal team, a campaign deliverable from a studio, or a batch of files uploaded during a content ingestion project. The file lands in the DAM.
Within seconds, the Librarian Agent begins working. The Content Typing Agent classifies the asset: this is a lifestyle image, or a product shot, or a mixed-content PDF. Based on that classification, it determines which metadata fields apply. The Metadata Agent then analyzes the content itself, populating the applicable fields. A detailed caption is generated describing what is visually present. Product category, primary colors, brand, image type, and any configured custom fields are populated using predictive metadata. Embedded XMP and IPTC data are extracted and mapped to metadata fields. For documents, OCR processes visible text and makes it available as searchable metadata.
If predictive metadata detects a risk signal such as a brand deviation, a compliance-relevant attribute, or a prohibited content pattern, a review notification is triggered. The reviewer receives the asset, the detected metadata values, and AI-generated annotation guidance. They review, annotate, approve, or reject. The asset moves into active status or goes back for revision.
The entire sequence happens automatically. No cataloger had to open the file. No contributor had to remember which controlled vocabulary values apply. No compliance reviewer had to find the file in a folder and remember to check it. The asset is enriched, discoverable, and routed correctly from the moment it arrived.
What the Evidence Shows
The operational argument for predictive metadata is supported by measurable outcomes across organizations that have moved from manual metadata creation to agentic enrichment at scale.

Arthrex, a global medical device company, faced the volume problem directly: more than 100,000 images requiring metadata that a manual process could not sustain at acceptable quality. After deploying an AI Metadata Agent to replace manual metadata creation, the agent generated detailed captions for every image and automatically populated metadata fields across the entire library. The outcome was a 130 percent increase in content discoverability within months, and a measurable reduction in asset requests from other departments as teams became able to find content independently rather than relying on DAM administrators.
SEH, a professional services firm managing thousands of proposals, resumes, project photos, and design files, experienced the timeliness and consistency problems simultaneously: assets existed in the system but were not findable because enrichment was inconsistent and delayed. After deploying the Librarian Agent to automate content enrichment, content creation time dropped by 88 percent. A scope creation process that previously required 90 minutes was reduced to 10, driven largely by the shift from recreating unfindable content to locating and reusing content that was now properly enriched and searchable.
Both outcomes point to the same underlying dynamic: the value unlocked by predictive metadata is not primarily in the metadata itself. It is in what reliable, consistent, structured metadata makes possible downstream.
The Shift This Represents
The metadata problem in DAM has always been treated as a human behavior problem. If contributors would just fill out the fields. If teams would just follow the governance policy. If admins would just keep the taxonomy current.
Predictive metadata reframes the problem entirely. Metadata quality is not primarily a behavior challenge. It is an infrastructure challenge. And the right infrastructure produces consistent, structured, actionable metadata as a byproduct of content entering the system, not as a task that competes with every other priority in a content operation.
The direction the industry is moving is clear: metadata enrichment that depends on human consistency at scale will continue to underperform, and platforms that embed predictive intelligence at the point of ingest will increasingly separate themselves in terms of search quality, governance capability, and downstream content operability.
When metadata is an automatic output of an agentic system rather than a manual input from contributors, it becomes reliable enough to power real downstream use: intelligent search that returns the right asset the first time, personalization engines that actually have the segment attributes they need, compliance workflows that catch risk before content moves, and content reuse that reduces the cost of recreating assets that already exist but could not be found.
That is not an incremental improvement to tagging. It is a structural change to what a DAM can do, and to what content operations teams can reasonably expect from the systems they manage.
See Predictive Metadata in Action
Explore Aprimo’s Librarian Agent in an interactive demo. See how AI automatically classifies assets, populates metadata, detects risks, and triggers workflows.

Aprimo is recognized as a leader in Digital Asset Management by Forrester, Gartner, and Frost & Sullivan. Aprimo’s Agentic DAM platform includes five categories of AI agents: Planning Agents, Librarian Agents, Critic Agents, Compliance Agents, and Production Agents, coordinated across the full content operations lifecycle.
FAQ
What is predictive metadata in digital asset management?
Predictive metadata is the automated population of specific, configured metadata fields in a DAM using AI analysis of an asset’s visual and textual content. Unlike general auto-tagging, which generates descriptive keywords, predictive metadata targets structured fields with controlled values such as product category, primary color, compliance classification, or audience segment attributes. It is applied at ingest, governed by the organization’s defined taxonomy, and requires no manual input from contributors.
What is the difference between predictive metadata and auto-tagging?
Auto-tagging uses visual recognition to generate keyword tags that describe what is visible in an image. Predictive metadata goes further by populating structured, configured fields in the DAM’s metadata schema: dropdown fields, controlled vocabulary categories, compliance-relevant attributes, and custom fields specific to the organization’s taxonomy. Auto-tagging produces descriptive output. Predictive metadata produces structured, actionable output that powers search, governance workflows, and downstream system integration.
What is a Librarian Agent in a DAM system?
A Librarian Agent is a persistent AI agent, or coordinated set of agents, within a DAM platform whose function is to automatically classify, enrich, and manage content metadata as assets enter the system. It operates continuously and independently of human scheduling, analyzing each asset at ingest to determine its content type, populate applicable metadata fields, extract embedded data, and trigger downstream workflows where needed. The Librarian Agent replaces manual cataloging as the primary mechanism for metadata quality in high-volume content environments.
Why does metadata quality degrade at scale in DAM programs?
Metadata quality degrades at scale for five structural reasons: taxonomy drift as controlled vocabularies fall behind business evolution; field population gaps as contributors skip fields under time pressure; context mismatches as single metadata models fail to serve multiple downstream systems; volume constraints as manual cataloging cannot keep pace with content production rates; and timeliness failures as metadata applied after ingest leaves assets invisible during the window when they are most needed. These failure modes compound each other and cannot be resolved through governance policy or contributor training alone.
How does predictive metadata support personalization programs?
Personalization engines driven by Customer Data Platforms require content to be tagged with audience and segment attributes that match the CDP’s data structure. Standard DAM taxonomies are designed for asset management and do not map to these segment fields. Predictive metadata addresses this by supporting parallel taxonomies: metadata fields mirroring the CDP’s segment attributes can be configured in the DAM and populated automatically on new and historical content, enabling the personalization engine to consume DAM assets directly without manual re-tagging or bridge processes.
